Предисловие.
Как сказали в комментариях к первой статье, что могут руки не дойти до второй статьи, как в воду глядели. Она лежала незавершенная очень долгое время. Сейчас подогнал чуть-чуть, только пришлось отказаться от многих деталей и пожеланий, которые высказывались в комментариях к первой части. Но думаю интерес все таки вызовет данное продолжение статьи, хоть и высказывались, что PBR банальная и избитая тема. В прочем я согласен, но что бы писать следующую статью все таки нужно завершить начатое ранее.
Кому интересно продолжение статьи добро пожаловать под кат
Знакомство со схемой.
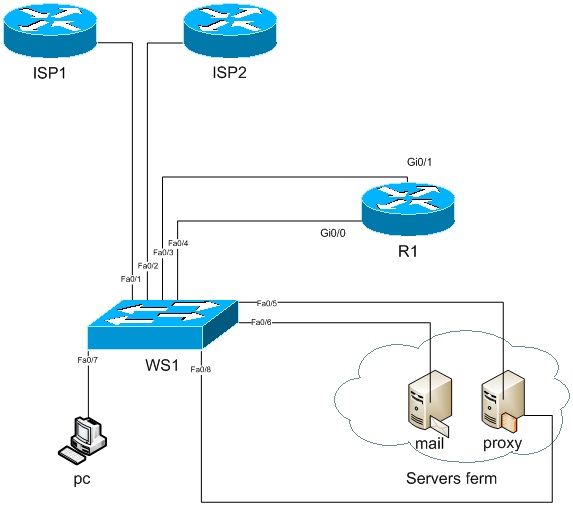
Для дальнейшего знакомства с PBR, я набросал виртуальную схему офиса. Состоит она из 3-х маршрутизаторов, коммутатора, 2-х серверов и символического клиента, который в единственном лице представляет пользовательские ПК:
1. Маршрутизатор нашего офиса (R1).
2. Маршрутизатор провайдера основного (ISP1).
3. Маршрутизатор резервного провайдера (ISP2).
4. Почтовый сервер (mail)
5. Прокси-сервер (proxy)
6. Коммутатор (ws1)
7. Клиент (PC)
Так же, я не отобразил на схеме удаленный офис, но в статье он будет подразумеваться.
И так легкое описание схемы. Есть у нас сеть пользователей, 192.168.0.0/27 им нужны сервисы такие как, внутренняя почта, интернет, и другие которые в нашей схеме не зафиксированы. Сервера будут жить у нас в сети 192.168.0.32/29 (на схеме отражены 2 сервера, сервер внутренней почты, и proxy-сервер). Ну и внешние сети (я возьму серые сети, подразумевая под ними белые). Итого получим следующий адресный план.
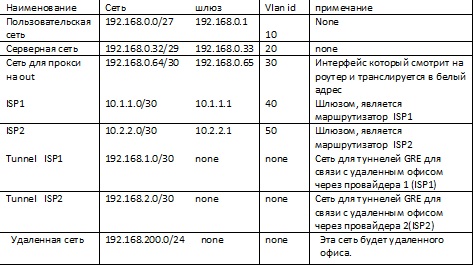
Исходные данные, мы отобразили теперь перейдем к конфигурации оборудования, вначале я настрою оборудование офиса виртуального, как говориться «что бы работало» (полные конфигурации не буду приводить так, как статья про PBR). При переносе исходных данных в конфигурацию мы получаем, вот такое:
R1#sh run | b int
interface Tunnel1
description ### tunnel over ISP1 ###
ip address 192.168.1.1 255.255.255.252
tunnel source 10.1.1.2
tunnel destination 10.0.0.2
!
interface Tunnel2
description ### tunnel over ISP2 ###
ip address 192.168.2.1 255.255.255.252
tunnel source 10.2.2.2
tunnel destination 10.0.0.2
!
interface GigabitEthernet0/0
no ip address
duplex auto
speed auto
!
interface GigabitEthernet0/0.10
description ### client network ###
encapsulation dot1Q 10
ip address 192.168.0.1 255.255.255.224
!
interface GigabitEthernet0/0.20
description ### servers network ###
encapsulation dot1Q 20
ip address 192.168.0.33 255.255.255.224
!
interface GigabitEthernet0/0.30
description ### proxy out int ####
encapsulation dot1Q 30
ip address 192.168.0.65 255.255.255.252
!
interface GigabitEthernet0/1
no ip address
duplex auto
speed auto
!
interface GigabitEthernet0/1.40
description ### ISP1 p-to-p ###
encapsulation dot1Q 40
ip address 10.1.1.2 255.255.255.252
!
interface GigabitEthernet0/1.50
description ### ISP2 p-to-p ###
encapsulation dot1Q 50
ip address 10.2.2.2 255.255.255.252
Конфигурацию Коммутатора ws1, я приводить не буду. Поверим на слово что все порты в своих вланах, порты, в mode trunk, пропускают только нужные вланы. Аналогично можно сказать про сервера, они настроены и корректно отрабатывают свою задачу.
Ситуация когда нужна просто гибкая маршрутизация.
Итак вот у нас есть виртуальный офис, и хотим мы контролировать пользователей, считать трафик и т.п. для этого у нас есть proxy сервер(далее просто proxy), следовательно нам нужно завернуть трафик от пользовательской сети, на proxy. Задача есть, приступаем к решению.
Для начала нужно выбрать сеть для которой мы будем «рисовать» карту маршрутизации.
Это можно делать 2-мя способами через ACL, или метить (применять) трафик, который проходит через логический интерфейс, направляем на porxy.
делаем карту либо так:
access-list 101 permit ip 192.168.0.0 0.0.0.31 any
!
route-map client permit 5
match ip address 101
set ip next-hop 192.168.0.35
либо так:
route-map clientif permit 5
match interface GigabitEthernet0/0.10
set ip next-hop 192.168.0.35
есть еще способ, без применения параметра, match, просто вешается карта с параметром set на интерфейс, но я не уверен в 100 процентной работоспособности, и чревато последствиями, применение его (теоретически), кому интересно можете попробовать посмотреть.
Что мы получаем в итоге. Весь клиентский трафик пойдет у нас на proxy, и дальше proxy уже будет думать советуясь со своей таблицей маршрутизации куда трафик отправить. При такой картине, у нас появляется маленький нюанс. Клиенты (MUA), обращаются к почтовому серверу (MTA), через лишний хоп (proxy), а это уже возможная лишняя проблема предоставления услуг, в частности потового сервиса. Ведь администраторы proxy, могут не только к примеру перегружать сервер, но и вывести из строя работоспособные настройки, да и банальная поломка железа на сервере, а вас как назло нет на месте и нет доступа к роутеру. В общем не совсем корректно, тут лучше обойти этот лишний хоп. Делается это тоже несколькими способами:
1. Способ это — прописать вместо ip next-hop, ip default next-hop. Тем самым карта не будет отрабатывать для mail, так как, он у нас находится в глобальной таблице маршрутизации в сети которая directly connection.
2. Способ переписать наш акцесс лист
access-list 101 deny ip 192.168.0.0 0.0.0.31 host 192.168.0.34
access-list 101 permit ip 192.168.0.0 0.0.0.31 any
Естественно, тут можно модифицировать, к примеру, что бы у нас обращение клиентов к серверам шло напрямую без участия proxy, тогда вместо:
access-list 101 deny ip 192.168.0.0 0.0.0.31 host 192.168.0.34
пишем
access-list 101 deny ip 192.168.0.0 0.0.0.31 192.168.0.34 0.0.0.31
Или нарисовать карту с портами. Т.е. к примеру вы хотите контролировать доступ по RDP, на proxy, но клиенты по почтовым портам ходили на прямую, то рисуем так листы:
access-list 101 deny tcp 192.168.0.0 0.0.0.31 host 192.168.0.34 eq smtp
access-list 101 permit ip 192.168.0.0 0.0.0.31 any
про ip locacl policy.
И так у нас 2 провайдера. Для начала настроим общение нашего роутера с провайдерами. Перво-наперво нарисуем, что бы интерфейсы на роутере отвечал через свой шлюз, это для того что бы избежать петли маршрутизации, т.е. откуда пакет пришел в наш роутер туда он и уйдет. Картину, которую мы пытаемся избежать, выглядит так: у нас есть один из шлюзов в интернет 10.1.1.1, прописан он на роутере как маршрут по умолчанию. При попытки попасть из интернета на роутер по адресу 10.2.2.2, до него пакеты дойдут, но в ответ он будет отправлять через шлюз 10.1.1.1 так как, он у нас маршрут по умолчанию. А там и канал может «лежать» и просто провайдера оборудование не будет знать про сеть 10.2.2.0/30, или задержки большие. Делаем следующие шаги:
а. Пишем 2 листа для 2-х независимых сетей провайдера.
access-list 105 permit ip 10.1.1.0 0.0.0.3 any
access-list 106 permit ip 10.2.2.0 0.0.0.3 any
б. рисуем карту маршрутизации
route-map r1 permit 10
match ip address 105
set ip next-hop 10.1.1.1
route-map r1 permit 15
match ip address 106
set ip next-hop 10.2.2.1
в. Применяем нашу карту, на локальную политику маршрутизатора.
ip local policy route-map r1
тут стоит отметить, что при применении карты к ip local policy будет перенаправление трафика, который генерируется на самом роутере, а трафик который не попадает под обработку роут мапа будет действовать согласно, глобальной политики маршрутизатора. Так же у нас есть и другие сети на маршрутизаторе, которые общаются только между сетями непосредственно подключенными к роутеру, для того что бы остальные сети так же имели шлюз по умолчанию достаточно добавить такого рода строку
route-map r1 permit 30
set ip next-hop 192.168.1.2
предполагается, что этот хоп находится на удаленном офисе, с которым нужно обмениваться трафиком с оставшимися сетями. Так как у нас 2 туннеля, через 2 провайдера, то тут справедливо сделать резервирование на случай падения основного, туннеля. Это делается с помощью SLA.
Его описали в достаточном объеме и не только на хабре, я этот момент опускаю.
немного о nat & pbr
На данный момент будем считать, что внутренняя маршрутизация у нас организована, по крайней мере, пользователи у нас ходят через proxy, в интернет к серверной сети они обращаются минуя proxy.
Но если мы оставим в таком состоянии, пользователи, прибыв на работу, захотят почитать любимые ресурсы в сети, проверить почту, а интернета у них, то нет, тогда они, убедившись что помимо личных ресурсов в сети, не работают и нужные по работе, тут сразу поднимется крик.
Что бы этого избежать, мы должны доделать дело до конца. Берем, транслируем адрес proxy в белые адреса провайдеров.
ip nat source route-map proxy1 interface GigabitEthernet0/1.40
ip nat source route-map proxy2 interface GigabitEthernet0/1.50
А тут «бабац» и не работает трансляция, nat и locacl policy, не отработают, так как для трансляции адресов, необходим маршрут в глобальной таблице маршрутизации. Т.е. необходимость прописать маршруты по умолчанию на 2-х провайдеров, никто не отменял. Ну и трекинг сюда же прикручиваем.
Маленькие мелочи и тонкости механизма.
В предыдущей части в комментариях, проскакивали вопросы и пожелания описать загрузку процессора маршрутизатора. Скажу что кушает он мало и видимой нагрузки не заметим. К примеру на каталисте 4948e при роутинге через PBR в районе 3-х гигов загрузки практически не наблюдается. Да и раз уж зашла тема по загрузке. То Скажу PBR с версии 12.0 поддерживает технологию cef (cisco express forvarding) она включена по умолчанию, для того что бы выключить cef для PBR достаточно дать команду ip route-cache policy на интерфейсе который держит карту (естественно на физическом а не на сабинтерфейсе.), который включает тем самым fast-switching который хранит маршруты в кеше и так же не сильно загружает процессор, но c fast-switching не поддерживает команду set ip default next-hop.
По этому, думаю стоит не экспериментировать, и использовать cef.
Ну и без описания и подробностей, скажу что проверять отрабатывает pbr или нет можно такими коммандами sh route-map all или имя непосредственно карты, наиболее важные данные показываются в виде:
Policy routing matches: 76013668 packets, 3726692270 bytes
debug ip policy тут не забываем, что можно положить роутер загрузив cpu
ключевые слова policy routed это значит что пакет ушел согласно нарисованой карты,
и policy rejected — normal forwarding обратная ситуация, когда пакет пошел согласно глобальной таблицы.
Параметры загрузки
Содержание
Введение
ПО Cisco IOS ® поддерживает несколько механизмов поддержки передачи трафика с минимальной задержкой и высокой пропускной способностью. В данном документе объясняется, как определить путь пакетов коммутации или переадресации Cisco IOS.
Примечание. В документе содержится описание только коммутации, быстрой коммутации и технологии Cisco Express Forwarding (CEF) процессов.
Предварительные условия
Требования
Использование данного документа требует наличия следующих знаний:
Программное обеспечение Cisco IOS
Платформы серии Cisco 1600, 2500 и 3600
Используемые компоненты
Настоящий документ не имеет жесткой привязки к устройству или какой-либо версии ПО.
Условные обозначения
Подробные сведения о применяемых в документе обозначениях см. в разделе Условные обозначения, используемые в технической документации Cisco.
Коммутация Cisco IOS
Коммутация Cisco IOS определяет поток пакетов, передаваемых через маршрутизатор. Точнее, он определяет скорость передачи пакетов через маршрутизатор, а также физические буферы хранения пакетов.
За всю историю существования Cisco IOS было разработано несколько методов коммутации. Некоторые из методов используются только на определенных платформах. CEF – новейший метод коммутации. Он был введен на многих платформах Cisco IOS основной версии 12.0, в частности, на платформах нижнего и среднего ценового диапазона, таких как Cisco серий 1600, 2500, и 3600.
Когда маршрутизатор получает пакет на маршрутизированный интерфейс, он сначала удаляет информацию о кадрах уровня 2 (L2). После этого пакет уровня 3 (L3) сохраняется в памяти ввода-вывода. Что произойдет дальше, зависит от пути коммутации, по которому следует пакет.
Этапы проверки
Следующие шаги используются для подтверждения следования пакетов по маршруту коммутации CEF:
Убедитесь, что функция CEF включена на глобальном уровне и на определенном интерфейсе.
Используйте команду ip cef в режиме глобальной конфигурации, чтобы включить (централизованно) функцию CEF.
Примечание. На маршрутизаторах серии Cisco 7200, в планируемых выпусках ПО Cisco IOS метод коммутации CEF принят по умолчанию.
Используйте команду show ip cef prefix, и подтвердите приведенные префиксы.
Убедитесь, что функция CEF активирована для заданного интерфейса.
Используйте команду show cef interface x/x, чтобы узнать, активна ли настройка коммутации "IP CEF switching enabled," или "IP distributed CEF (dCEF) switching enabled."
Используйте команду show ip interface, чтобы отобразить активные методы коммутации Cisco IOS.
В приведенных выходных данных флаг "No CEF" показывает, что функция CEF отключена из-за применения команды no ip route-cache cef на определенном интерфейсе. Флаг "CEF" означает, что CEF работает. В установившемся режиме оба флага не отображаются. Идентификатор ошибки Cisco CSCdr80269 ( только для зарегистрированных пользователей ) устраняет редкие случаи, в которых появляются оба флага. Дополнительные сведения по идентификаторам ошибок приведены в Средстве обнаружения ошибок ( только для зарегистрированных пользователей ).
Подтвердите, что большинство пересылаемых через маршрутизатор пакетов подвергаются CEF-коммутации.
Используйте команду show int x/x stat для определения числа пакетов и байт, переадресованных маршрутизатором через "Processor", а не через "Route cache". Обратите внимание, что "Route cache" включает пакеты быстрой коммутации и пакеты коммутации CEF.
Используйте команду show ip cache, чтобы определить, существует ли запись кэша IP, которая показывает, что пакет использует путь быстрой коммутации. Быстрая коммутация строит кэш маршруты по требованию, чтобы ускорить передачу пакетов на маршрутизатор. Код драйвера, выполняющийся на интерфейсе оборудования, временно передает управление коду быстрой коммутации, который осуществляет поиск кадра и других сведений, основанных на предыдущем переданном пакете, в кэше маршрутов. Если кэш маршрутов содержит запись, то с помощью кода быстрой коммутации осуществляются попытки передать пакеты непосредственно на интерфейс назначения.
Ниже описана специальная процедура проверки пересылаемых пакетов с использованием CEF.
Активируйте CEF с помощью команды ip cef.
Выполните команду clear ip cache, чтобы удалить записи кэша быстрой коммутации.
Запустите поток трафика.
Выполните команду show ip cache. Подтвердите, что с момента CEF-коммутации пакетов в кэше быстрого переключения не отображалось записей.
Выполните команду show interface stats и подтвердите возрастание обращений для входящего кэша маршрутов.
Примечание. Счетчик кэша маршрутов включает как пакеты быстрой коммутации, так и пакеты коммутации CEF.
На входящем интерфейсе отключите CEF с помощью команды no ip route-cache cef.
Выполните команду show interface stats и подтвердите возрастание обращений для кэша маршрутов.
Выполните команду show ip cache и убедитесь, что после того, как Cisco IOS переключилось на быструю коммутацию, появились записи.
Выполните команду no ip route-cache на исходящем интерфейсе для отключения быстрой коммутации. Пакеты на совпадающих входных интерфейсах являются пакетами process switched (с поддержкой коммутации обработки).
Примечание. Настройка коммутации обработки (process switching) в сети с большим объемом трафика не рекомендуется.
Если вы подтвердили, что функция CEF включена в интерфейсе маршрутизатора, и определили, что большая часть пакетов не подвергается CEF-коммутации, введите следующие команды для посылки отчета о проблеме в Центр технической поддержки Cisco.
Примечание. Обратитесь к документу Важная информация о командах отладки, прежде чем использовать команды debug.
show cef interface x/x – отображает сведения об интерфейсе, касающиеся CEF.
show ip cef prefix – отображает запись префикса в базе данных переадресации (FIB)
show adjacency interface detail – отображает рекурсивные и прямые префиксы, которые определяются с помощью смежности.
show cef not-cef-switched – отображает пакеты, которые не подвергаются CEF-коммутации.
debug ip cef drop – отображает сведения отладки для пакетов, отброшенных функцией CEF.
Входной интерфейс определяет путь коммутации Cisco IOS, который используется пакетом. Рассмотрите данные эмпирические правила при включении и отключении методов коммутации на определенном интерфейсе.
Быстрая коммутация (кэш IP-маршрутов)
Другими словами, необходимо включить функцию CEF на входящем интерфейсе для выполнения CEF-коммутации пакетов. Так как CEF принимает решение по переадресации на входе, используйте команду no ip route-cache cef во входном интерфейсе для отключения CEF. В отличие от этого, из-за того, что после коммутации пакета Cisco IOS создает запись кэша быстрой коммутации, то пакет, поступающий в интерфейс process-switched и выходящий через интерфейс с поддержкой быстрой коммутации, будет подвергаться быстрой коммутации. Используйте команду no ip route-cache для выходного интерфейса для отключения быстрой коммутации.
Сведения о CEF "Punt"
Термин "punt" используется Cisco, чтобы описать действие драйвера интерфейсного устройства по передаче пакетов "вниз" на следующий уровень быстрой коммутации. В данном списке определен порядок предпочитаемых методов Cisco IOS (от самых быстрых до самых медленных).
Событие "punt" происходит при следующих условиях:
Следующий более низкий уровень не предоставляет корректный путь или, в случае CEF, корректную смежность. Другими словами, если процесс поиска CEF не сможет найти допустимую запись в базе данных переадресации, пакет передается на следующий доступный путь коммутации или отбрасывается.
Определенная функция или инкапсуляция L2 на нижнем уровне не поддерживается. Если CEF поддерживает определенную функцию, информация о принадлежности пакета передается через набор системных программ в тракте функций ("feature path") CEF.
Функция требует специального управления.
Punt-смежность в CEF устанавливается в том случае, когда в CEF не поддерживается какая-либо выходная функция. В ходе коммутации пакетов, CEF перебрасывает все пакеты, предназначенные для данной смежности, в следующий наилучший режим коммутации с тем, чтобы обеспечить коммутацию всех пакетов.
При неполной смежности функция CEF предполагает, что маршрутизатор в целом (включая все другие пути маршрутизации) не знает, как достичь смежного узла. Пакеты перенаправляются для коммутации обработки, чтобы запустить протокол разрешения, (например протокол разрешения адресов (ARP)), что приведет к последующему установлению смежности. В этом состоянии CEF перебрасывает на следующий путь коммутации один пакет каждые две секунды, чтобы избежать переполнения пакетами. Таким образом, в данном состоянии запросы ICM-эхо на IP-адрес могут завершаться неудачно примерно в 50% случаев, и будет отображаться шаблон запроса: ". ". Данное состояние также появляется, если таблица CEF повреждена, на что указывает отличия в выходных данных команд show ip route и show ip cef для конкретного IP-адреса.
Примечание. Линейная карта (LC) на гигабитном коммутаторе-маршрутизаторе (GSR) создает ответы на запросы "ICMP-эхо" внутри CEF. Если пакет не направлен ни на один из локальных адресов GSR, то никакие процессы выполняться не будут. Коммутация выполняется либо в аппаратном обеспечении, либо посредством прерываний в dCEF, в зависимости от используемой LC.
На GSR быстрая коммутация и коммутация обработки недоступны. При невозможности определить префикс получателя в запись переадресации в таблицах входящих линейных плат пакет отбрасывается. Только пакеты, соответствующие подобранным смежностям, передаются процессору гигабитного маршрутизатора (GRP). Кроме того, на GSR процессор LC CPU не перебрасывает пакеты на GRP для обработки функциями; LC посылает ICMP сообщение о недоступности (в том случае, если команда no ip unreachables не задана). На GSR единственным трафиком, отправляемым на GRP, являются пакеты, направленные на интерфейс маршрутизатора, или исходящие пакеты маршрутизатора.

I am doing a VRRP lab (in boson netsim) and I noticed they have no ip route-cache command on the vlan 1 interface on both the access and distribution layer switches. VRRP is implemented on the distribution switch.
I gather this is telling CEF not to cache the next hop — this would be required if the master/backup roles changed . Yes. No.
If this is the case, I can understand why it’s enabled on the access layer switch but why would it be needed on the distribution as well?
- 112261 Просмотров
- Метки: нет (добавить)
- Join this discussion now: Войдите / Register
1. Re: no ip-route cache

The ‘no ip route-cache’ command enables process switching on an interface.
Cisco layer 3 devices have three switching modes, Process Switching, Fast Switching, and Cisco Express Forwarding switching. Most current Cisco models have CEF enabled by default because of the amount of information it caches and how efficient it switches traffic.
Seeing the ‘no ip route-cache’ command means that all packets entering the layer-3 interface will be process switched by the CPU instead of hardware. This can possibly over-burden the CPU when high amounts of traffic is needing to be switched. Fast switching was created to relieve this issue by caching route information and only process-switching the first packet of a flow. A flow is a stream of packets that have headers with mostly identical pieces of information. This generally means, that a flow of packets are all headed to the same destination. The first packet of the flow would be process switched. The information gathered by the forwarding device would then be compiled or broken down into simpler pieces of information and cached so the lookup process would not occur for every packet in the flow. Compiled information was stored in hardware lookup tables and is handled independently of the CPU. This why Fast Switching is better than Process Switching when forwarding traffic for production.
CEF builds upon the idea of Fast Switching by caching information prior to flows entering the device. Also the algorithm is more complex and accurate. Some advanced protocols require IP CEF be enabled. I’m pretty sure only one switching method can be enabled on an interface at one time.
Now, why NetSim chose to add that command is something that is unclear to me. It is just a simulation and there may be a good reason—I’m not sure. Maybe someone can add additional information to this thread.
Hope that clears up things for you.
- Мне нравится Показать отметки "Мне нравится" (13) (13)
- Действия
- Join this discussion now: Войдите / Register
2. Re: no ip-route cache

Good explanation Mike. I wonder if they chose the "no ip route-cache" due to the small size of the network, and perhaps to expose the student to the technology. It’s something that isn’t always configured by the nework engineer, or paid attention to, but as you pointed out is very helpful in building a more robust foundation for the newtork.
- Мне нравится Показать отметки "Мне нравится" (0) (0)
- Действия
- Join this discussion now: Войдите / Register
3. Re: no ip-route cache
Older switches and routers will sometimes have the no ip route-cache command enabled by default. Either because at the time the SVI can’t support CEF switching or because it was "more normal" to process switch packets between virtual interfaces and therefore is default. Today, modern Cisco switches using CEF for layer 3 switching on all interfaces (both physical and virtual).
The VRRP packets are not CEF switched however. If a packet is destined to the device itself (and not passing through it), it needs to be addressed by the control plane (also known as the route processor). Therefore CEF performs an action called "punting" where the packet is moved out of CEF and is handled by the route processor through process switching. Even today, there is plenty of reasons why CEF punts packets to the route-processor: TTL expired, IP options enabled, non-IP packets and ICMP redirects are to name a few.
A very good reson to disable CEF on an interface is to gather debugging information for transient traffic. Debugs don’t have the ability to gather information from traffic passing through the device that is handled by CEF. Therefore, a ‘debug ip packet [detail]’ won’t "see" traffic passing through the device if handled by CEF. You will need to disable CEF on the interfaces with the ‘no ip route-cache’ command in order for the debug process to detect this traffic. ‘Debug ip packet’ only sees traffic that is processed switched (also known as interrupt switching) and not CEF switched. Disabling CEF on a device can cause the CPU to spike if the device is in production so handle with care. Disable CEF on lab devices first before expermenting with production.
- Мне нравится Показать отметки "Мне нравится" (6) (6)
- Действия
- Join this discussion now: Войдите / Register
4. Re: no ip-route cache

Thomas -one reason can be the task is asking for a specific output for the trace command. This is due to the fact that with the no ip route-cache the packets will be distributed between the outgoing interfaces. Let’s say you have a switch with a SVI and two possible connections to the outside workd through two routers.
In this case the packets will be distributed. check it with a traceroute und you see the difference.
- Мне нравится Показать 1 отметку "Мне нравится" (1)
- Действия
- Join this discussion now: Войдите / Register
5. Re: no ip-route cache
Short and to the point. I like that. Good answer
- Мне нравится Показать отметки "Мне нравится" (0) (0)
- Действия
- Join this discussion now: Войдите / Register
6. Re: no ip-route cache

Michael, how can you expect hardware based switching in a Simulation in the first place? I believe the software configures process switching itself. Never used NetSim, so I could be wrong too.