Что такое случайность в компьютере? Как происходит генерация случайных чисел? В этой статье мы постарались дать простые ответы на эти вопросы.
В программном обеспечении, да и в технике в целом существует необходимость в воспроизводимой случайности: числа и картинки, которые кажутся случайными, на самом деле сгенерированы определённым алгоритмом. Это называется псевдослучайностью, и мы рассмотрим простые способы создания псевдослучайных чисел. В конце статьи мы сформулируем простую теорему для создания этих, казалось бы, случайных чисел.
Определение того, что именно является случайностью, может быть довольно сложной задачей. Существуют тесты (например, колмогоровская сложность), которые могут дать вам точное значение того, насколько случайна та или иная последовательность. Но мы не будем заморачиваться, а просто попробуем создать последовательность чисел, которые будут казаться несвязанными между собой.
Часто требуется не просто одно число, а несколько случайных чисел, генерируюемых непрерывно. Следовательно, учитывая начальное значение, нам нужно создать другие случайные числа. Это начальное значение называется семенем, и позже мы увидим, как его получить. А пока давайте сконцентрируемся на создании других случайных значений.
Один из подходов может заключаться в том, чтобы применить какую-то безумную математическую формулу к семени, а затем исказить её настолько, что число на выходе будет казаться непредсказуемым, а после взять его как семя для следующей итерации. Вопрос только в том, как должна выглядеть эта функция искажения.
Давайте поэкспериментируем с этой идеей и посмотрим, куда она нас приведёт.
Функция искажения будет принимать одно значение, а возвращать другое. Назовём её R.
Начнём с того, что R — это простая функция, которая всего лишь прибавляет единицу.
Если значение нашего семени 1, то R создаст ряд 1, 2, 3, 4, . Выглядит совсем не случайно, но мы дойдём до этого. Пусть теперь R добавляет константу вместо 1.
Если с равняется, например, 7, то мы получим ряд 1, 8, 15, 22, . Всё ещё не то. Очевидно, что мы упускаем то, что числа не должны только увеличиваться, они должны быть разбросаны по какому-то диапазону. Нам нужно, чтобы наша последовательность возвращалась в начало — круг из чисел!
Числовой круг
Посмотрим на циферблат часов: наш ряд начинается с 1 и идёт по кругу до 12. Но поскольку мы работаем с компьютером, пусть вместо 12 будет 0.
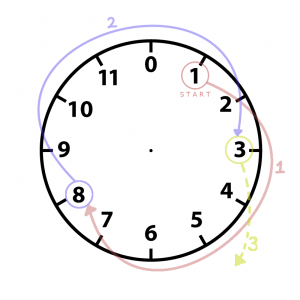
Теперь начиная с 1 снова будем прибавлять 7. Прогресс! Мы видим, что после 12 наш ряд начинает повторяться, независимо от того, с какого числа начать.
Здесь мы получаем очень важно свойство: если наш цикл состоит из n элементов, то максимальное число элементов, которые мы можем получить перед тем, как они начнут повторяться это n.
Теперь давайте переделаем функцию R так, чтобы она соответствовала нашей логике. Ограничить длину цикла можно с помощью оператора модуля или оператора остатка от деления.
На этом этапе вы можете заметить, что некоторые числа не подходят для c. Если c = 4, и мы начали с 1, наша последовательность была бы 1, 5, 9, 1, 5, 9, 1, 5, 9, . что нам конечно же не подходит, потому что эта последовательность абсолютно не случайная. Становится понятно, что числа, которые мы выбираем для длины цикла и длины прыжка должны быть связаны особым образом.
Если вы попробуете несколько разных значений, то сможете увидеть одно свойство: m и с должны быть взаимно простыми.
До сих пор мы делали "прыжки" за счёт добавления, но что если использовать умножение? Умножим х на константу a.
Свойства, которым должно подчиняться а, чтобы образовался полный цикл, немного более специфичны. Чтобы создать верный цикл:
- (а — 1) должно делиться на все простые множители m
- (а — 1) должно делиться на 4, если m делится на 4
Эти свойства вместе с правилом, что m и с должны быть взаимно простыми составляют теорему Халла-Добелла. Мы не будем рассматривать её доказательство, но если бы вы взяли кучу разных значений для разных констант, то могли бы прийти к тому же выводу.
Настало время поговорить о самом интересном: выборе первоначального семени. Мы могли бы сделать его константой. Это может пригодиться в тех случаях, когда вам нужны случайные числа, но при этом нужно, чтобы при каждом запуске программы они были одинаковые. Например, создание одинаковой карты для каждой игры.
Еще один способ — это получать семя из нового источника каждый раз при запуске программы, как в системных часах. Это пригодится в случае, когда нужно общее рандомное число, как в программе с бросанием кубика.
Когда мы применяем функцию к её результату несколько раз, мы получаем рекуррентное соотношение. Давайте запишем нашу формулу с использованием рекурсии:
Где начальное значение х — это семя, а — множитель, с — константа, m — оператор остатка от деления.
То, что мы сделали, называется линейным конгруэнтным методом. Он очень часто используется, потому что он прост в реализации и вычисления выполняются быстро.
В разных языках программирования реализация линейного конгруэнтного метода отличается, то есть меняются значения констант. Например, функция случайных чисел в libc (стандартная библиотека С для Linux) использует m = 2 ^ 32, a = 1664525 и c = 1013904223. Такие компиляторы, как gcc, обычно используют эти значения.
Существуют и другие алгоритмы генерации случайных чисел, но линейный конгруэнтный метод считается классическим и лёгким для понимания. Если вы хотите глубже изучить данную тему, то обратите внимание на книгу Random Numbers Generators, в которой приведены элегантные доказательства линейного конгруэнтного метода.
Генерация случайных чисел имеет множество приложений в области информатики и особенно важна для криптографии.
 Случайные числа используются во многих алгоритма х машинного обучения. Например, распространенной задачей является выбор случайной строки матрицы. В C# код может выглядеть так:
Случайные числа используются во многих алгоритма х машинного обучения. Например, распространенной задачей является выбор случайной строки матрицы. В C# код может выглядеть так:
В этой статье я покажу, как генерировать случайные числа с помощью четырех разных алгоритмов: алгоритма Лемера (Lehmer), линейного конгруэнтного алгоритма ( linear congruential algorithm), алгоритма Вичмана-Хилла (Wichmann-Hill) и алгоритма Фибоначчи с запаздываниями (lagged Fibonacci algorithm).
Но зачем обременять себя созданием собственного генератора случайных чисел (random number generator, RNG), когда в Microsoft .NET Framework уже есть эффективный и простой в использовании класс Random? Существует два сценария, где вам может понадобиться создать свой RNG. Во-первых, в разные языки программирования встроены разные алгоритмы генерации случайных чисел, а значит, если вы пишете код, который будет переноситься на несколько языков, можно создать собственный RNG, чтобы реализовать его во всех нужных вам языках. Во-вторых, некоторые языки, в частности R, имеют лишь глобальный RNG, поэтому, если вы захотите создать несколько генераторов, вам придется писать свой RNG.
Хороший способ получить представление о том, куда я клоню в этой статье, — взглянуть на демонстрационную программу на рис. 1. Демонстрационная программа начинает с создания очень простого RNGЮ используя алгоритм Лемера. Затем с помощью RNG генерируется 1000 случайных целых чисел между 0 и 9 включительно. За кулисами записываются счетчики для каждого из сгенерированных целых чисел, которые потом отображаются на экране. Этот процесс повторяется для линейного конгруэнтного алгоритма, алгоритма Вичмана-Хилла и алгоритм Фибоначчи с запаздываниями.
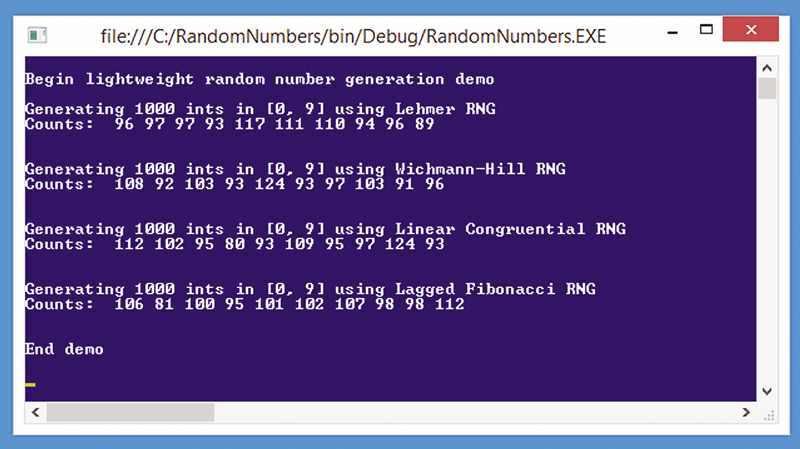
Рис. 1. Демонстрация упрощенной генерации случайных чисел
В этой статье предполагается, что вы умеете программировать хотя бы на среднем уровне, но ничего не знаете о генерации случайных чисел. Демонстрационная программа написана на C#, но, поскольку один из основных случаев использования собственной генерации случайных чисел — написание портируемого кода, эта программа разработана так, чтобы ее можно было легко транслировать на другие языки.
Алгоритм Лемера
Самый простой приемлемый метод генерации случайных чисел — алгоритм Лемера. (Для простоты я использую термин «генерация случайных чисел» вместо более точного термина «генерация псевдослучайных чисел».) Выраженный в символьном виде, алгоритм Лемера представляет собой следующее:
На словах это звучит так: «новое случайное число является старым случайным числом, умножаемым на константу a, после чего над результатом выполняется операция по модулю константы m». Например, предположим, что в некий момент текущее случайное число равно 104, a = 3 и m = 100. Тогда новое случайное число будет равно 3 * 104 mod 100 = 312 mod 100 = 12. Вроде бы просто, но в реализации этого алгоритма много хитроумных деталей.
Чтобы создать демонстрационную программу, я запустил Visual Studio, выбрал шаблон C# Console Application и назвал проект RandomNumbers. В этой программе нет значимых зависимостей от .NET Framework, поэтому подойдет любая версия Visual Studio.
После загрузки кода шаблона в окно редактора я переименовал в окне Solution Explorer файл Program.cs в более описательный RandomNumbersProgram.cs, и Visual Studio автоматически переименовала класс Program за меня. В начале кода я удалил все лишние выражения using, оставив только ссылки на пространства имен верхнего уровня System и Collections.Generic.
Затем я добавил класс с именем LehmerRng для реализации RNG-алгоритма Лемера. Код показан на рис. 2. Версия алгоритма Лемера за 1988 год использует a = 16807 и m = 2147483647 (которое является int.MaxValue). Позднее, в 1993 году Лемер предложил другую версию, где a = 48271 как чуть более качественную альтернативу. Эти значения берутся из математической теории. Демонстрационный код основан на знаменитой статье С. К. Парка (S. K. Park) и К. У. Миллера (K. W. Miller) «Random Number Generators: Good Ones Are Hard to Find».
Рис. 2. Реализация алгоритма Лемера
Проблема реализации в том, чтобы предотвращать арифметическое переполнение. Алгоритм Лемера использует ловкий алгебраический трюк. Значение q является результатом m / a (целочисленное деление), а значение r равно m % a (m по модулю a).
При инициализации RNG Лемера начальным (зародышевым) значением можно использовать любое целое число в диапазоне [1, int.MaxValue – 1]. Многие RNG имеют конструктор без параметров, который получает системные дату и время, преобразует их в целое число и использует в качестве начального значения.
RNG Лемера вызывается в методе Main демонстрационной программы:
Каждый вызов метода Next возвращает значение в диапазоне [0.0, 1.0) — больше или равно 0.0 и строго меньше 1.0. Шаблон (int)(hi – lo) * Next + lo) будет возвращать целое число в диапазоне [lo, hi–1].
Алгоритм Лемера весьма эффективен, и в простых сценариях я обычно выбираю именно его. Но заметьте, что ни один алгоритм из представленных в этой статье не обладает надежностью криптографического уровня и что их следует применять только в ситуациях, где не требуется статической строгости (statistical rigor).
Алгоритм Вичмана-Хилла
Этот алгоритм датируется 1982 годом. Идея Вичмана-Хилла заключается в генерации трех предварительных результатов и последующего их объединения в один финальный результат. Код, реализующий алгоритм Вичмана-Хилла, представлен на рис. 3. Демонстрационный код основан на статье Б. А. Вичмана (B. A. Wichmann) и А. Д. Хилла (I. D. Hill) «Algorithm AS 183: An Efficient and Portable Pseudo-Random Number Generator».
Рис. 3. Реализация алгоритма Вичмана-Хилла
Поскольку алгоритм Вичмана-Хилла использует три разных генерирующих уравнения, он требует трех начальных значений. В этом алгоритме три m-значения равны 30269, 30307 и 30323, поэтому вам понадобятся три начальных значения в диапазоне [1, 30000]. Вы могли бы написать конструктор, принимающий эти три значения, но тогда вы получили бы несколько раздражающий программный интерфейс. В демонстрации применяется параметр с одним начальным значением, генерирующим три рабочих зародыша.
Вызов RNG Вичмана-Хилла осуществляется по тому же шаблону, что и других демонстрационных RNG:
Алгоритм Вичмана-Хилла лишь немного труднее в реализации, чем алгоритм Лемера. Преимущество первого над вторым в том, что алгоритм Вичмана-Хилла генерирует более длинную последовательность (более 6 000 000 000 000 значений) до того, как начнет повторяться.
Линейный конгруэнтный алгоритм
Оказывается, и алгоритм Лемера, и алгоритм Вичмана-Хилла можно считать особыми случаями так называемого линейного конгруэнтного алгоритма (linear congruential, LC). Выраженный в виде уравнения, LC выглядит так:
Это точно соответствует алгоритму Лемера с добавлением дополнительной константы c. Включение c придает универсальному LC-алгоритму несколько лучшие статистические свойства по сравнению с алгоритмом Лемера. Демонстрационная реализация LC-алгоритма показана на рис. 4. Код основан на стандарте POSIX (Portable Operating System Interface).
Рис. 4. Реализация линейного конгруэнтного алгоритма
LC-алгоритм использует несколько битовых операций. Здесь идея в том, чтобы в базовых математических типах работать не с целым типом (32 бита), а с длинным целым (64 бита). По окончании 32 из этих битов (с 16-го по 47-й включительно) извлекаются и преобразуются в целое число. Этот подход дает более качественные результаты, чем при использовании просто 32 младших или старших битов, но за счет некоторого усложнения кодирования.
В демонстрации генератор случайных чисел LC вызывается так:
Заметьте, что в отличие от генераторов Лемера и Вичмана-Хилла генератор LC может принимать начальное значение 0. Конструктор в демонстрации LC копирует значение входного параметра seed непосредственно в член класса — поле seed. Многие распространенные реализации LC выполняют предварительные манипуляции над входным начальным значением, чтобы избежать генерации хорошо известных серий начальных значений.
Алгоритм Фибоначчи с запаздываниями
Этот алгоритм, выраженный уравнением, выглядит так:
Если на словах, то новое случайное число является тем, которое было сгенерировано 7 раз назад, плюс случайное число, сгенерированное 10 раз назад, и деленное по модулю на большое значение m. Значения (7, 10) можно изменять, как я вскоре поясню.
Допустим, что в некий момент времени последовательность сгенерированных чисел следующая:
где 561 — самое последнее из сгенерированных значений. Если m = 100, то следующим случайным числом будет:
Заметьте, что в любой момент вам всегда нужны 10 самых последних сгенерированных значений. Поэтому ключевая задача в алгоритме Фибоначчи с запаздываниями состоит в генерации начальных значений, необходимых для запуска процесса. Демонстрационная реализация алгоритма Фибоначчи с запаздываниями приведена на рис. 5.
Рис. 5. Реализация алгоритма Фибоначчи с запаздываниями
Демонстрационный код использует предыдущие случайные числа X(i–7) и X(i–10) для генерации следующего случайного числа. В научно-исследовательской литературе по этой тематике значения (7, 10) обычно обозначаются (j, k). Существуют другие пары (j, k), которые можно применять для алгоритма Фибоначчи с запаздываниями. Несколько значений, рекомендованных в хорошо известной книге «Art of Computer Programming» (Addison-Wesley, 1968), — (24,55), (38,89), (37,100), (30,127), (83,258), (107,378).
Чтобы инициализировать (j, k) в RNG Фибоначчи с запаздываниями, вы должны предварительно заполнить список значениями k. Это можно сделать несколькими способами. Однако наименьшее из начальных значений k обязательно должно быть нечетным. В демонстрации применяется грубый метод копирования значения параметра seed для всех начальных значений k с последующим удалением первой 1000 сгенерированных значений. Если значение параметра seed четное, тогда первое из значений k выставляется равным 11 (произвольному нечетному числу).
Чтобы предотвратить арифметическое переполнение, метод Next использует тип long для вычислений и математическое свойство: (a + b) mod n = [(a mod n) + (b mod n)] mod n.
Заключение
Позвольте мне подчеркнуть, что все четыре RNG, представленные в этой статье, предназначены только для некритичных случаев применения. С учетом этого я прогнал все RNG через набор хорошо известных базовых тестов на степень случайности, и они прошли эти тесты. Но даже при этом коварство RNG всем хорошо известно, и время от времени даже в стандартных RNG обнаруживаются дефекты, иногда лишь спустя годы их использования. Например, в 1960-х годах IBM распространяла реализацию линейного конгруэнтного алгоритма под названием RANDU, которая, как оказалось, обладала невероятно плохими качествами. А в Microsoft Excel 2008 была выявлена ужасно проблемная реализация алгоритма Вичмана-Хилла.
Нынешний фаворит в генерации случайных чисел — алгоритм Фортуна (Fortuna) (названный в честь римской богини удачи). Алгоритм Фортуна был опубликован в 2003 году и основан на математической энтропии плюс сложных шифровальных методах, таких как AES (Advanced Encryption System).
Джеймс Маккафри (Dr. James McCaffrey) — работает на Microsoft Research в Редмонде (штат Вашингтон). Принимал участие в создании нескольких продуктов Microsoft, в том числе Internet Explorer и Bing. С ним можно связаться по адресу jammc@microsoft.com.
Выражаю благодарность за рецензирование статьи экспертам Microsoft Крису Ли (Chris Lee) и Кирку Олинику (Kirk Olynyk).